Prometheus联邦监控(Grafana集群+Influxdb...)
弃用方案仅供技术参考
配置清单
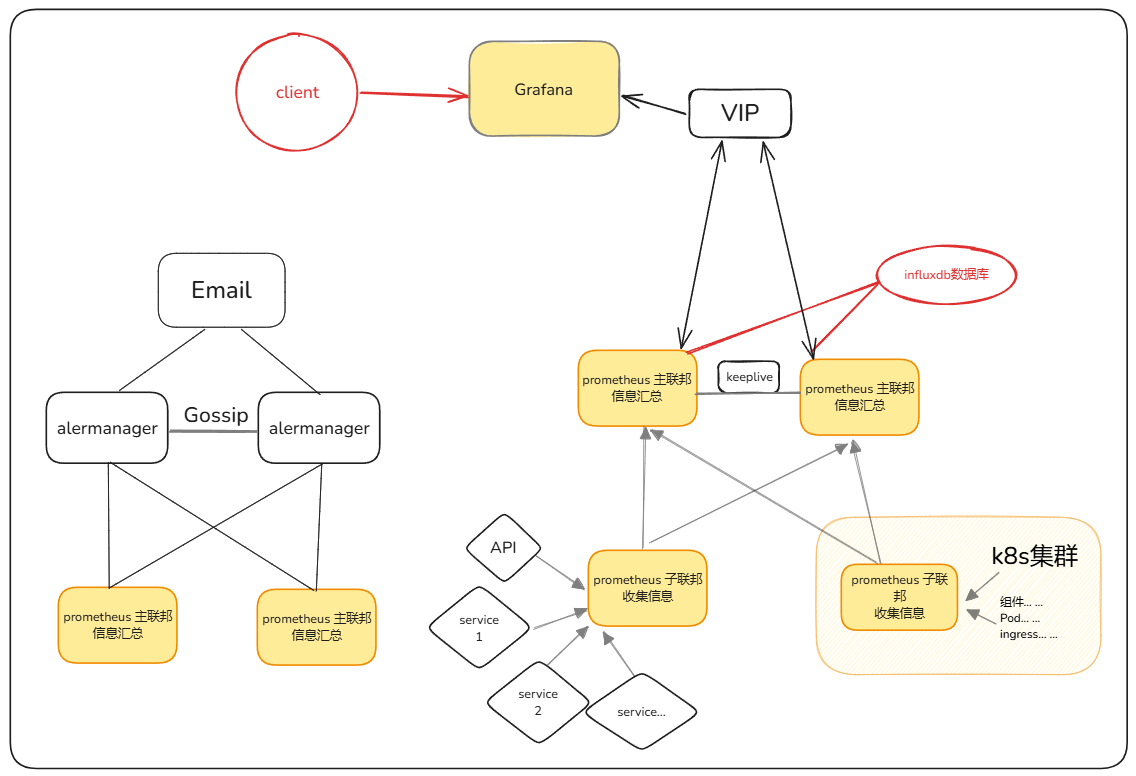
一、联邦集群的应用
1.部署prometheus服务
下载prometheus (在四台节点上安装)
#安装服务
mkdir /usr/local/prometheus
wget https://www.gmqgmq.cn/upload/prometheus-3.2.0.linux-amd64.tar.gz
tar -zxvf prometheus-3.2.0.linux-amd64.tar.gz -C /usr/local/prometheus
#创建prometheus链接
ln -sv /usr/local/prometheus/prometheus-3.2.0.linux-amd64 /usr/local/prometheus/prometheus
cd /usr/local/prometheus/prometheus
#手动启动
nohup ./prometheus --config.file=prometheus.yml &#创建Prometheus启动脚本
vim /etc/systemd/system/prometheus.service
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target
[Service]
Restart=on-failure
WorkingDirectory=/opt/prometheus/prometheus/
ExecStart=/opt/prometheus/prometheus/prometheus --config.file=/opt/prometheus/prometheus/prometheus.yml
[Install]
WantedBy=multi-user.target#启动prometheus
systemctl restart prometheus
#添加开机启动
systemctl enable prometheus2.配置子联邦节点到node抓取数据
export信息收集 (在被监控端部署)
wget www.gmqgmq.cn/upload/node_exporter-1.8.2.linux-amd64.tar.gz
mkdir node-exporter
tar -zxvf node_exporter-1.8.2.linux-amd64.tar.gz -C node-exporter
#进入目录 启动服务
sudo nohup ./node_exporter &
#查看端口是否启用 有信息则正确
netstat -antp | grep 9100
#tcp6 0 0 :::9100 :::* LISTEN 6034/./node_exporte 子联邦node1 (配置收集信息 此处以node_export举例)
vim prometheus.yml
- job_name: "prometheus-node1"
static_configs:
- targets: ["被监控端主机IP:端口"]子联邦node2(配置收集信息 此处以node_export举例)
vim prometheus.yml
- job_name: "prometheus-node2"
static_configs:
- targets: ["192.168.100.13:9100"]3.prometheus server 收集节点
vim prometheus.yml
# 添加以下配置,增加联邦集群节点 到prometheus server节点。
- job_name: 'prometheus-federate-12'
scrape_interval: 10s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
- '{__name__=~"node.*"}'
static_configs:
- targets: ['192.168.100.12:9090']
- job_name: 'prometheus-federate-13'
scrape_interval: 10s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
- '{__name__=~"node.*"}'
static_configs:
- targets: ['192.168.100.13:9090']
#检查配置文件语法
./promtool check config ./prometheus.yml
#重启prometheus
systemctl restart prometheus
#手动启动
nohup ./prometheus --config.file=prometheus.yml &登录server查看 是否收到了子联邦的数据
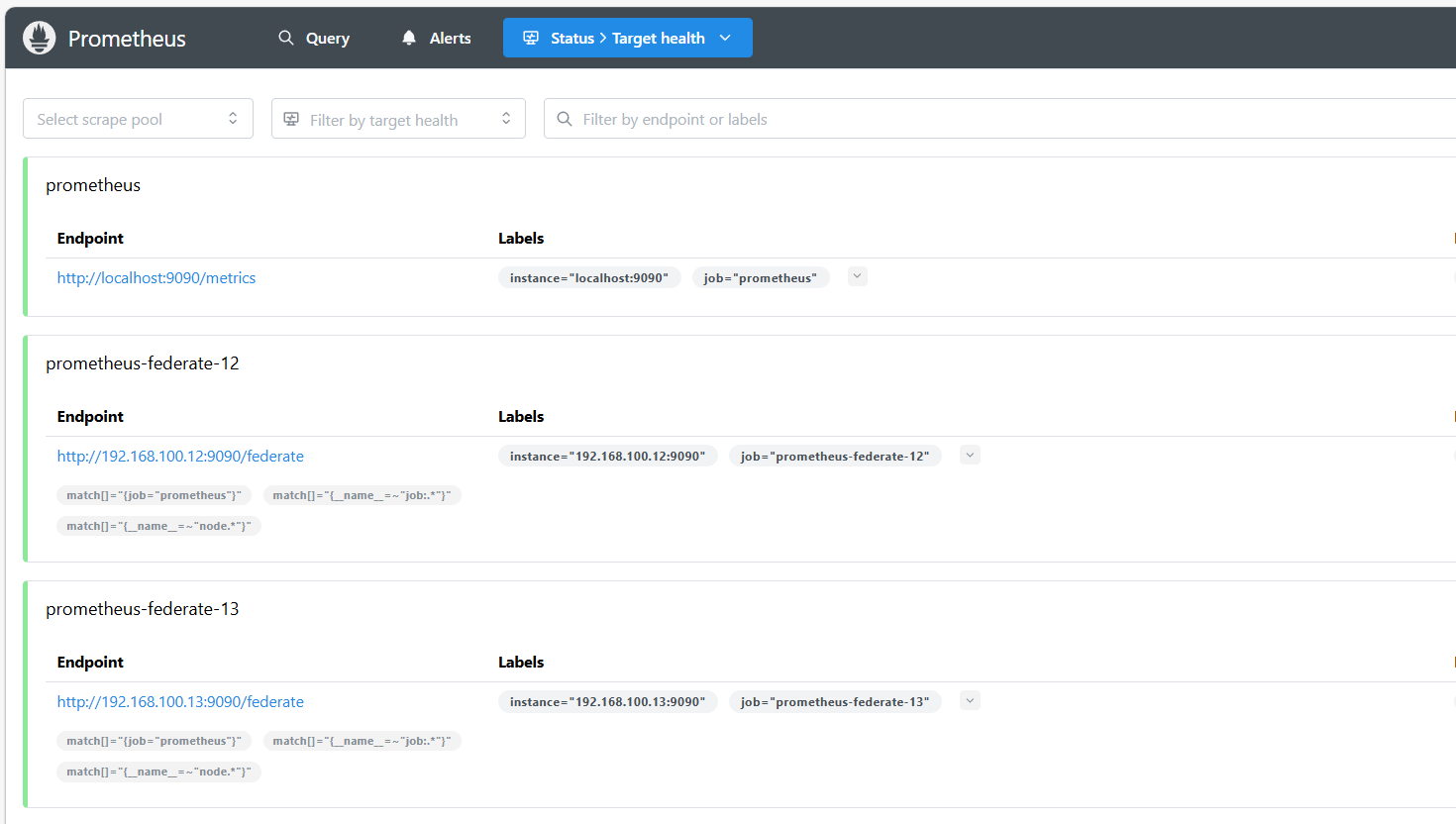
二、prometheus数据持久化和高可用
这里采用influxdb数据库实现数据持久化
influxdb简介
InfluxDB是一个时间序列数据库,旨在处理高写入和查询负载。 它是TICK堆栈的组成部分。 InfluxDB旨在用作涉及大量带时间戳数据的任何用例的后备存储,包括DevOps监控,应用程序指标,物联网传感器数据和实时分析。
以下是InfluxDB目前支持的一些功能,使其成为处理时间序列数据的绝佳选择:
专为时间序列数据编写的自定义高性能数据存储。 TSM引擎允许高摄取速度和数据压缩
完全使用go语言编写,并编译为一个单独的二进制文件.没有额外的依赖
简单,高性能的读写HTTP APIS
通过插件支持其他数据提取协议.比如:Graphite,collectd,和OpenTSDB
类SQL查询语言,方便数据的查询聚合
将tag索引,以便更快的查询速度
数据维护策略有效的移除过期数据
连续查询自动计算聚合数据,使定期查询更高效
可能由于自己的yum源不够全,通过yum install的方式无法安装influxdb,后采用下载influxdb的rpm包的方式安装部署
influxdb提供了prometheus的对接端口有如下几个:
/api/v1/prom/read
/api/v1/prom/write
/api/v1/prom/metrics1.配置go环境(数据库服务器)
1.下载软件包并解压
mkdir /root/influxdb
cd /root/influxdb
wget https://www.gmqgmq.cn/upload/go1.8.3.linux-amd64.tar.gz
tar -zxvf go1.8.3.linux-amd64.tar.gz
mv go /usr/local/
2.配置环境变量
vim /etc/profile
export GOROOT=/usr/local/go
export GOBIN=$GOROOT/bin
export GOPKG=$GOROOT/pkg/tool/linux_amd64
export GOARCH=amd64
export GOOS=linux
export GOPATH=/go
export PATH=$PATH:$GOBIN:$GOPKG:$GOPATH/bin
#source生效
source /etc/profile
3.查看go版本
[root@prometheus ~]# go version
2.部署influxdb数据库
1.下载软件包
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.8.4.x86_64.rpm
2.安装influxdb
rpm -ivh influxdb-1.8.4.x86_64.rpm
3.启动influxdb
systemctl start influxdb.service
systemctl enable influxdb
#以指定配置文件启动Influx:
#influxd -config /etc/influxdb/influxdb.conf
#连接数据库:
#influx -precision rfc3339 或influx
#指定端口连接:
#influx -port 8087
#参数:-precision为设置显示时间格式,如果没有设置,返回的时间类型字段显示为时间戳,使用rfc3339返回的时间格式为:2020-05-12T16:37:53.189100300Z

3.修改influxdb数据存放路径
vim /etc/influxdb/influxdb.conf
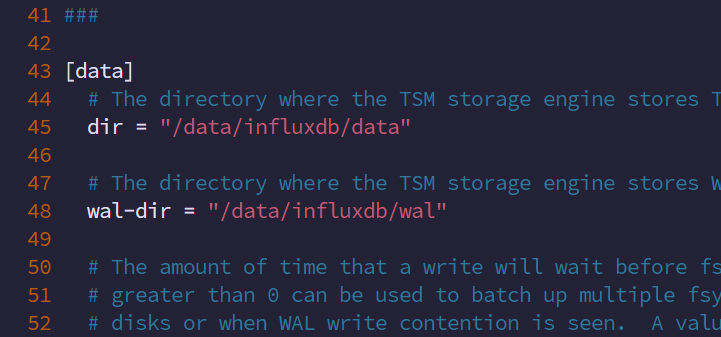
创建数据目录
mkdir -p /data/influxdb/{meta,data,wal}
chown -R influxdb.influxdb /data/influxdb/
#重启
systemctl restart influxdb数据文件已经生成
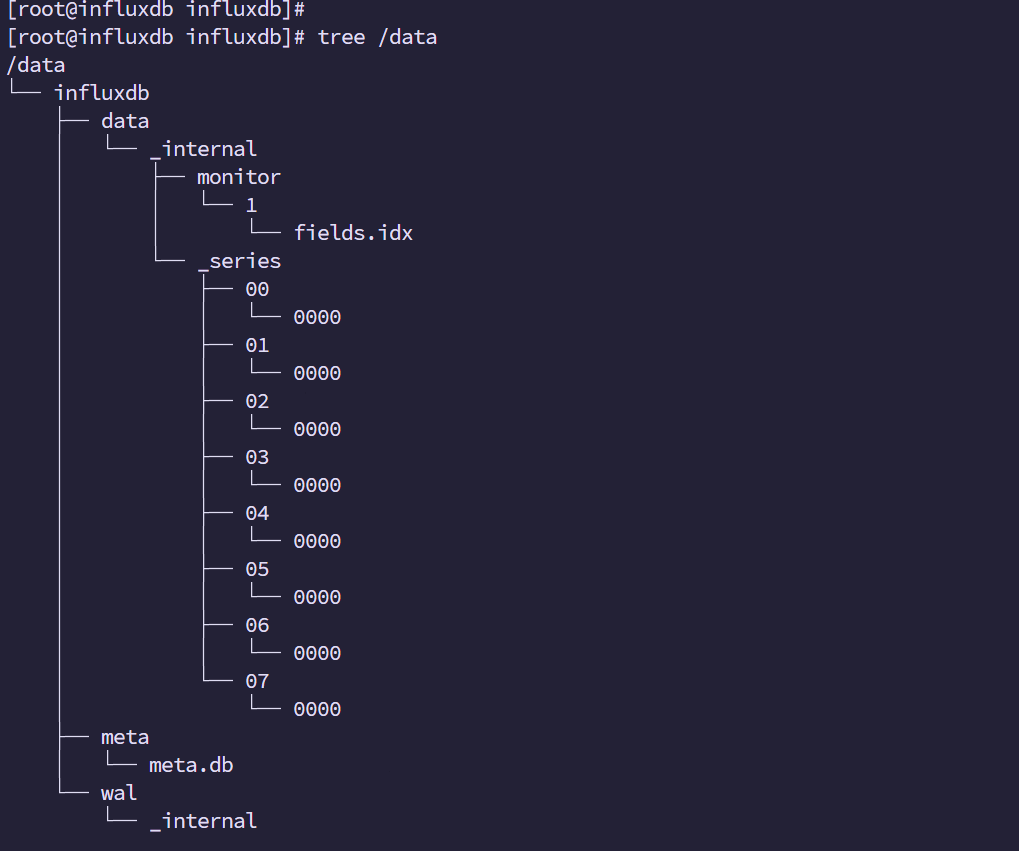
4.创建prometheus数据库(数据库端)
1、创建数据库
curl -XPOST http://192.168.100.13:8086/query --data-urlencode "q=CREATE DATABASE prometheus"
2、进入数据库
influx -precision rfc3339
3、查看数据库是否创建
> show databases
——————————————————
name: databases
name
----
_internal
prometheus5.准备remote_storage_adapter(数据库配置)
1.remote_storage_adapter下载
wget https://www.gmqgmq.cn/upload/remote_storage_adapter
2.连接influxdb
chmod a+x remote_storage_adapter
cp remote_storage_adapter /usr/bin
cd /usr/bin
3.配置变量
vim /etc/profile
export PATH=$PATH:/usr/local/go/bin
source /etc/profile
4.运行服务(指定DB数据库IP地址)
nohup ./remote_storage_adapter --influxdb-url=http://localhost:8086/ --influxdb.database="prometheus" --influxdb.retention-policy=autogen &
5.查看是否运行
ps aux | grep remote_storage_adapter
6.将remote加入服务注册
[root@prometheus ~]# vim /usr/lib/systemd/system/remote_storage_adapter.service
[Service]
Restart=on-failure
ExecStart=/usr/bin/remote_storage_adapter --influxdb-url=http://192.168.81.210:8086 --influxdb.database=prometheus --influxdb.retention-policy=autogen
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl enable remote_storage_adapter
systemctl start remote_storage_adapter
systemctl status remote_storag7.配置prometheus主、备联邦连接influxdb数据库
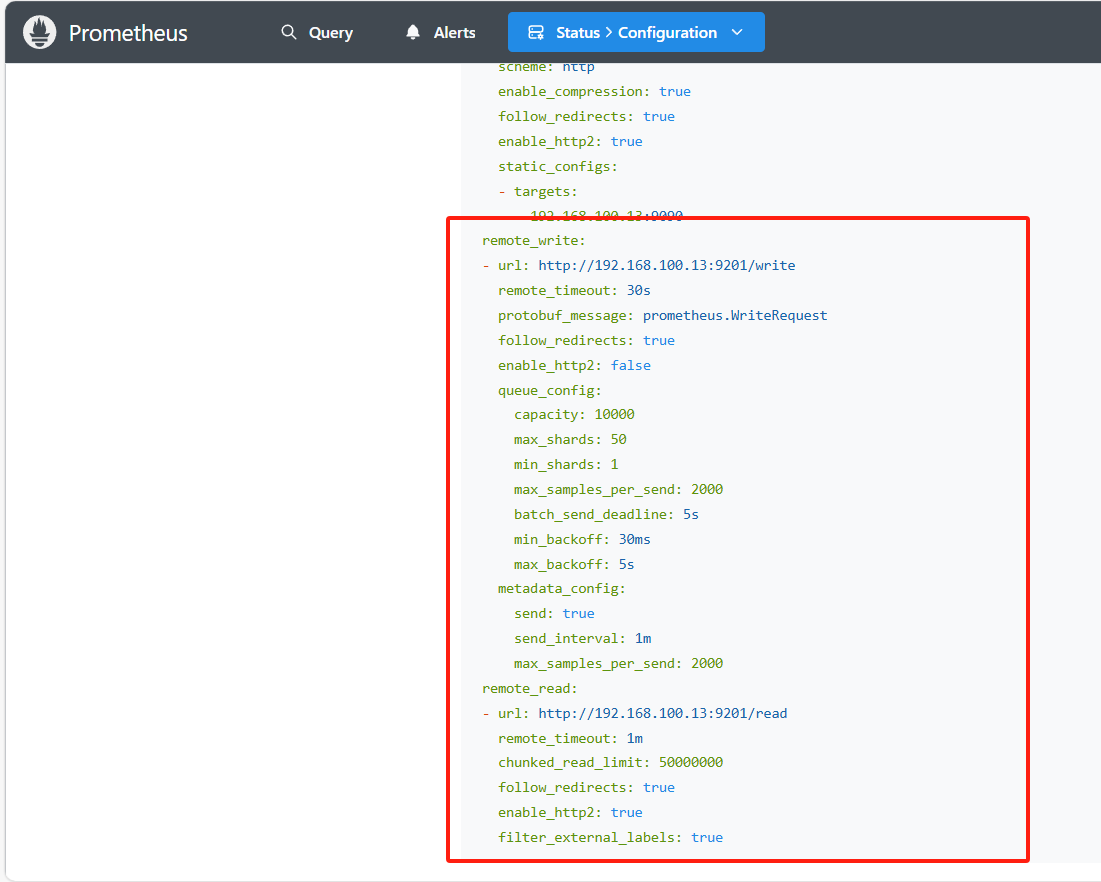
vim /usr/local/prometheus/prometheus/prometheus.yml
remote_write:
- url: "http://192.168.100.13:9201/write"
remote_read:
- url: "http://192.168.100.13:9201/read"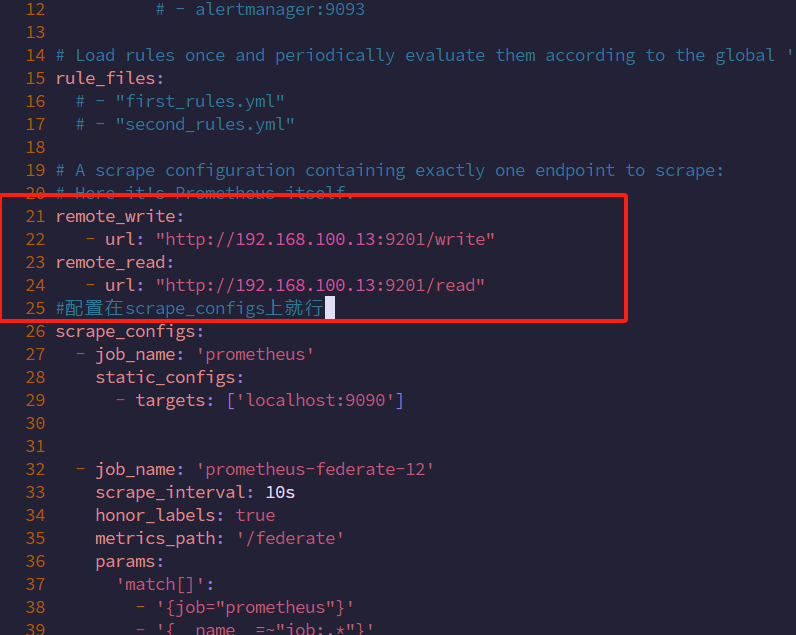
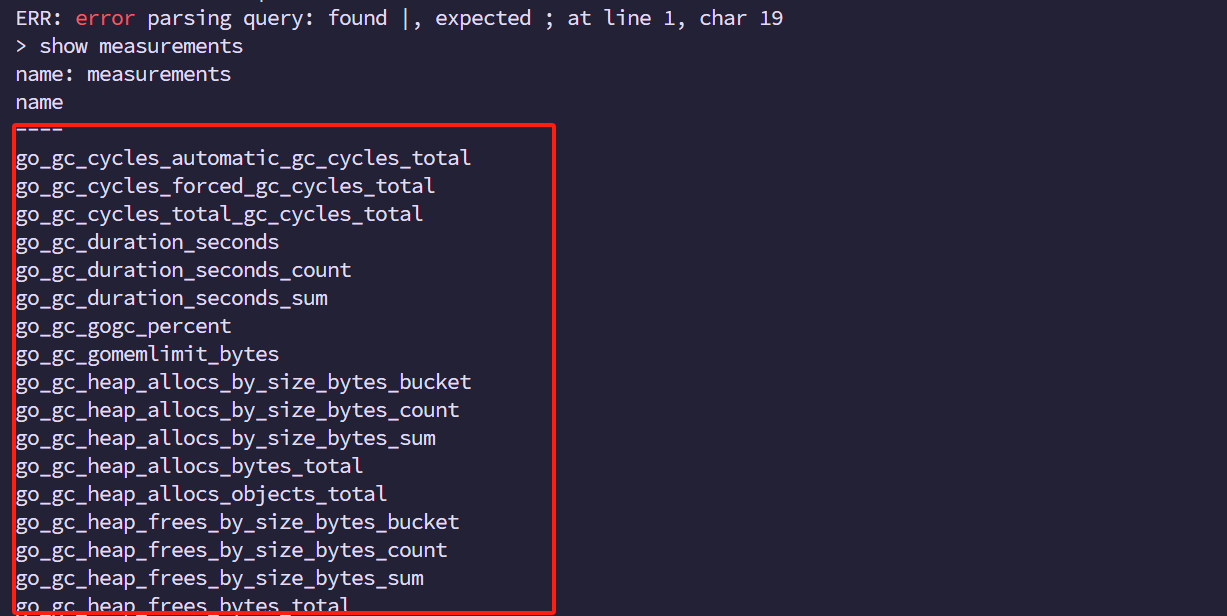
查看数据库是否有数据
配置数据存储时间
show retention policies on prometheus #查看过期时间
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 true
duration 代表过期时间 0是不过期
可以设置过期时间就是保存时间
alter retention policy autogen on prometheus duration 180d replication 1 default;#更改过期时间
create retention policy autogen on prometheus duration 180d replication 1 default;创建过期时间 唯一需要注意的就是后续的数据时间戳是否完全一直,如果出现数据写入时间错位就可能造成数据重复。
三、Keeplived+LVS高可用负载(两台汇总联邦一主一备)
1.配置虚拟网卡
cd /etc/sysconfig/network-scripts/
cp ifcfg-lo ifcfg-lo:1
vim ifcfg-lo:1#IP修改为漂移IP 也就是你要配置的VIP
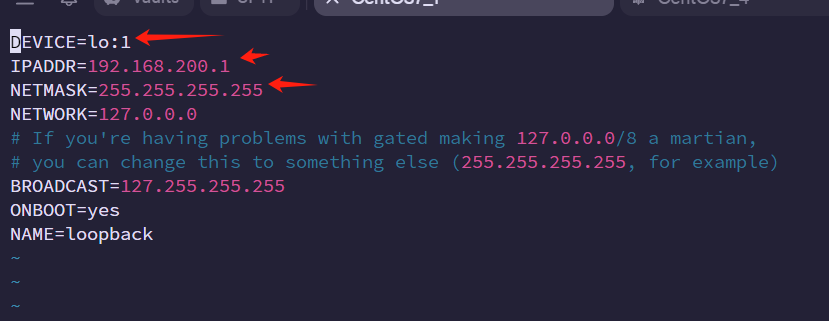
systemctl restart network2.配置内核参数文件
vim /etc/sysctl.conf
net.ipv4.ip_forward = 1
net.ipv4.conf.lo.arp_ignore = 1
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.default.arp_ignore = 1
net.ipv4.conf.lo.arp_announce = 1
net.ipv4.conf.all.arp_announce = 1
net.ipv4.conf.default.arp_announce = 1
sysctl -p3.开放路由
route add -host 192.168.200.1 dev lo:1
4.部署keepllived+LVS调度
yum -y install keepalived配置LVS主配置文件
vim /etc/keepalived/keepalived.conf

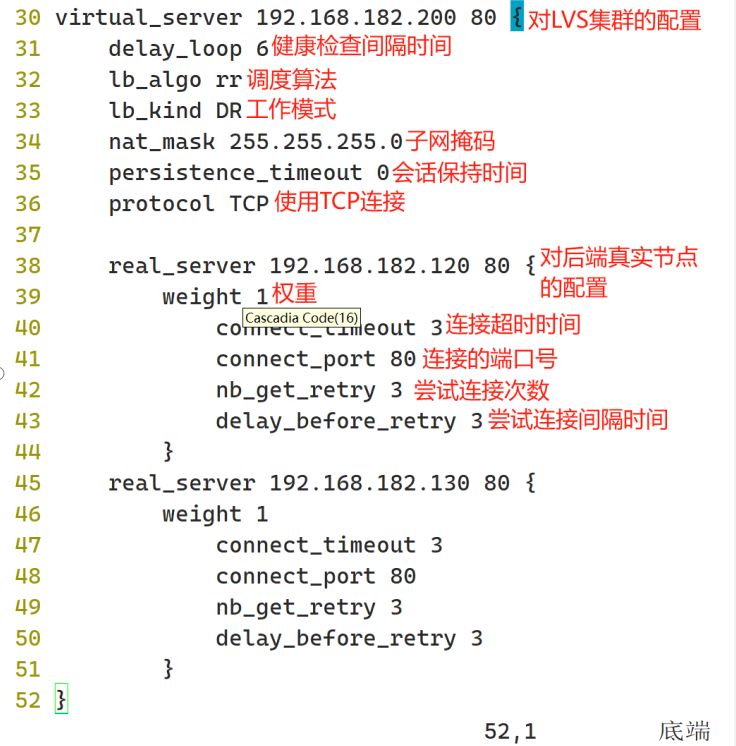
后面的文件内容删除
将master的配置文件传到BACKUP上面(记得自己手动备份原配置文件)
scp /etc/keepalived/keepalived.conf root@192.168.100.14:/etc/keepalived/配置LVS从配置文件
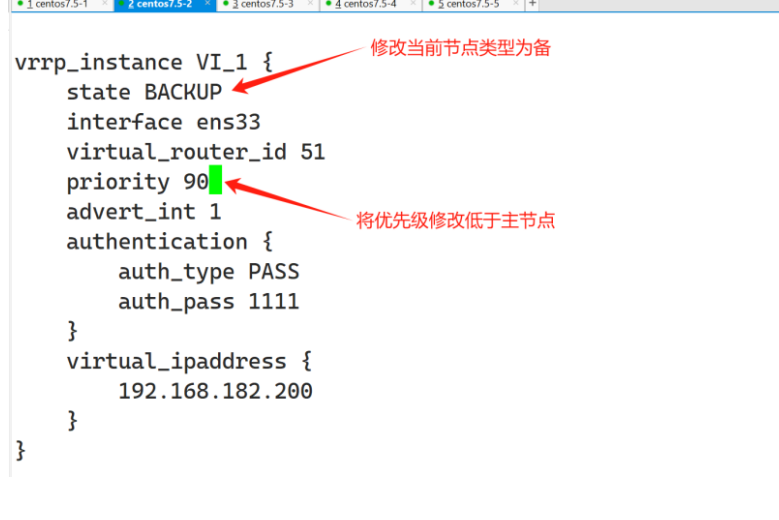
Keeplived配置文件:
启动主从服务器的服务
systemctl restart keepalived.service
#查看主从的漂移IP配置是否正常
ip a | grep ens33
systemctl stop firewalld
#或者
iptables -F主节点代理到漂移IP


grafana验证(安装之后验证)
数据可以正常找到
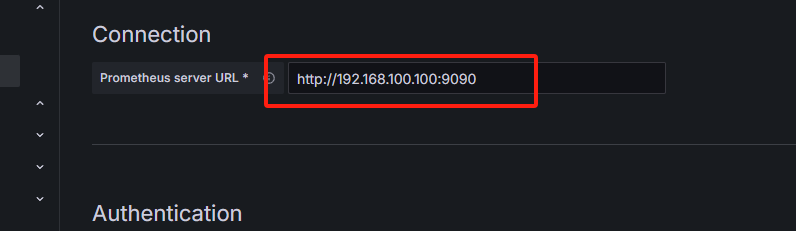
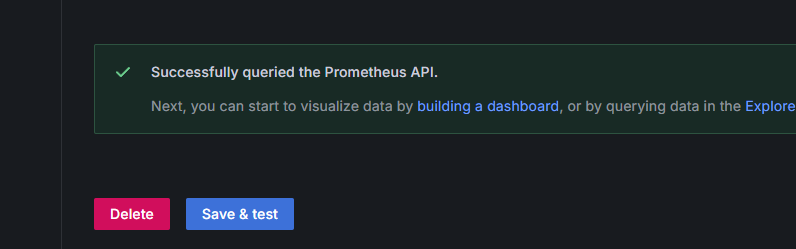
四、grafana
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-11.5.2.linux-amd64.tar.gz
tar -zxvf grafana-enterprise-11.5.2.linux-amd64.tar.gz1.将grafana注册为服务
vim /usr/lib/systemd/system/grafana-server.service
[Unit]
Description=Grafana
After=network.target
[Service]
Type=notify
ExecStart=/data/grafana/bin/grafana-server -homepath /data/grafana
Restart=always # 设置为总是重启
[Install]
WantedBy=multi-user.target
#重载
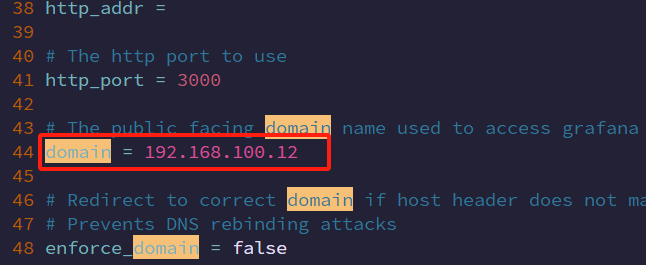
sudo systemctl daemon-reload2.修改配置文件
cd conf vim defaults.ini
启动服务
systemctl start grafana-server.service访问
账号密码都为:admin
因为是数据持久化 prometheus做了,grafana一般作为可视化所用,它没有太大的集群需求,如果怕它出现问题或者访问用户太多不够用 做个LVS负载均衡高可用足矣
grafana 要求(按照Node总量和问题数量进行配置,下面列出问题设备和设备信息) 。。。。。
五、alertmanager集群部署
1.安装alertmanager
获取安装包(部署两台:192.168.100.11 192.168.100.14)
#创建服务目录
mkdir alertmanager && cd alertmanager
#拉取服务软件包
wget https://github.com/prometheus/alertmanager/releases/download/v0.28.0/alertmanager-0.28.0.linux-amd64.tar.gz
#解压服务
tar -zxvf alertmanager-0.28.0.linux-amd64.tar.gz
mv alertmanager-0.28.0.linux-amd64 /usr/local/alertmanager
cd /usr/local/alertmanager
#启动服务
nohup /usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml &
#查看服务是否运行
lsof -i :9093
——————————————————————————————————————————————————————————————————————
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
alertmana 87538 root 7u IPv6 529954 0t0 TCP *:copycat (LISTEN)
#关闭服务
pkill alertmanager2.注册服务
cat > /usr/lib/systemd/system/alertmanager.service << EOF
[Service]
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
[Install]
WantedBy=multi-user.target
[Unit]
Description=alertmanager
After=network.target
EOF不要在启动服务了 下面配置集群 需要占用9093端口
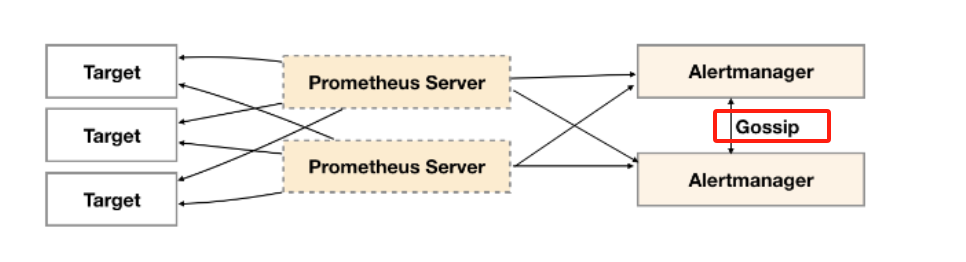
3.alert加入集群
以两台机器为例
这就相当于两个实例构成一个集群,两个之间通信通过各自开放的端口,前者开放8101,后者开放8101,同时后者通过cluster.peer来设置自己通过192.168.100.11:8101加入集群,所以这里先在11上运行开放,在这个过程会开放通讯,然后直接去14上运行然后就是等,等待Gossip 同步完成、节点连接与同步。

192.168.100.11
killall alertmanager
./alertmanager --web.listen-address=":9093" --cluster.listen-address="192.168.100.11:8001" --config.file=/usr/local/alertmanager/alertmanager.yml --storage.path=/data/alertmanager/ > /var/log/alertmanager-1.log 2>&1 &192.168.100.14
killall prometheus
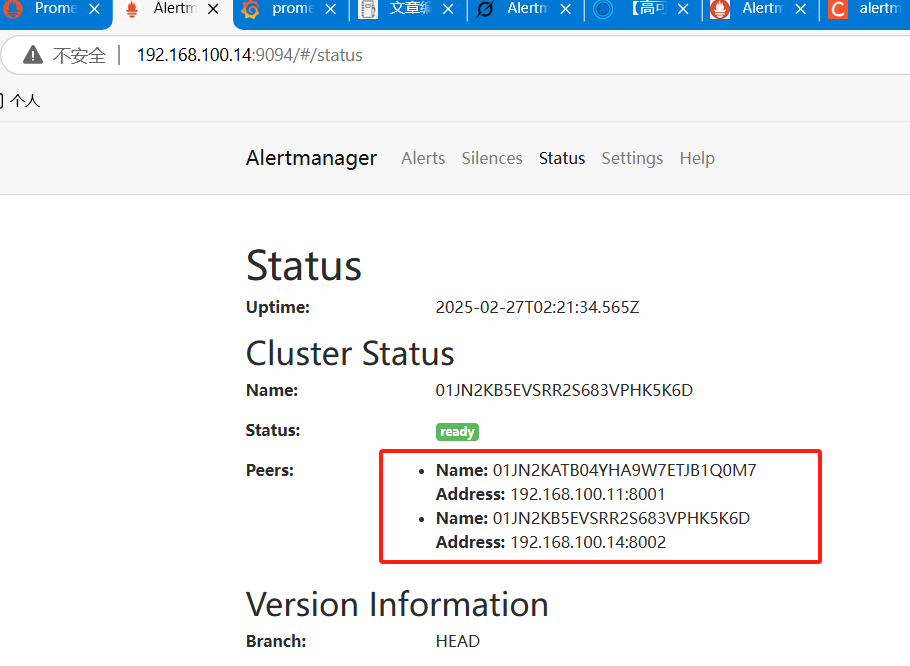
./alertmanager --web.listen-address=":9094" --cluster.listen-address="192.168.100.14:8002" --cluster.peer=192.168.100.11:8001 --config.file=/usr/local/alertmanager/alertmanager.yml --storage.path=/data/alertmanager2/ > /var/log/alertmanager-2.log 2>&1 &登录alertmanager可以看到两台节点都加上来了

4.Prom集成Alert组件添加告警配置目录(两台主联邦)
vim /usr/local/prometheus/prometheus.yml

- "rules/*.yml"
顺便吧alert也加到监控中
- job_name: "alertmanager"
static_configs:
- targets: ["192.168.100.11:9093","192.168.100.14:9094"]
重启prometheus
killall prometheus
nohup ./prometheus --config.file=prometheus.yml &六、配置Alertmanager告警邮箱(两台相同)
1.配置告警邮箱
因为要求邮箱报警 这里就配置基于邮箱的
在配置告警邮箱前,先配置邮箱授权码:CCCCR32XXXXYCtQb
保存下来
到alertmanager配置目录 备份配置文件
[root@pro-master alertmanager]# mv alertmanager.yml alertmanager.yml.bak
[root@pro-master alertmanager]# pwd
/usr/local/alertmanagervim alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:465'
smtp_from: 'teustgmq@163.com'
smtp_auth_username: 'trustgmq@163.com'
smtp_auth_password: 'KVUxxxxxxxxYCtQb'
smtp_require_tls: false
smtp_hello: '163.com'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 5m
repeat_interval: 1m
receiver: 'mail'
receivers:
- name: 'mail'
email_configs:
- to: 'trustgmq@163.com'2.配置alertmanager告警规则
#上面配置了报警的配置目录下面咱们创建该目录
/usr/local/prometheus/prometheus
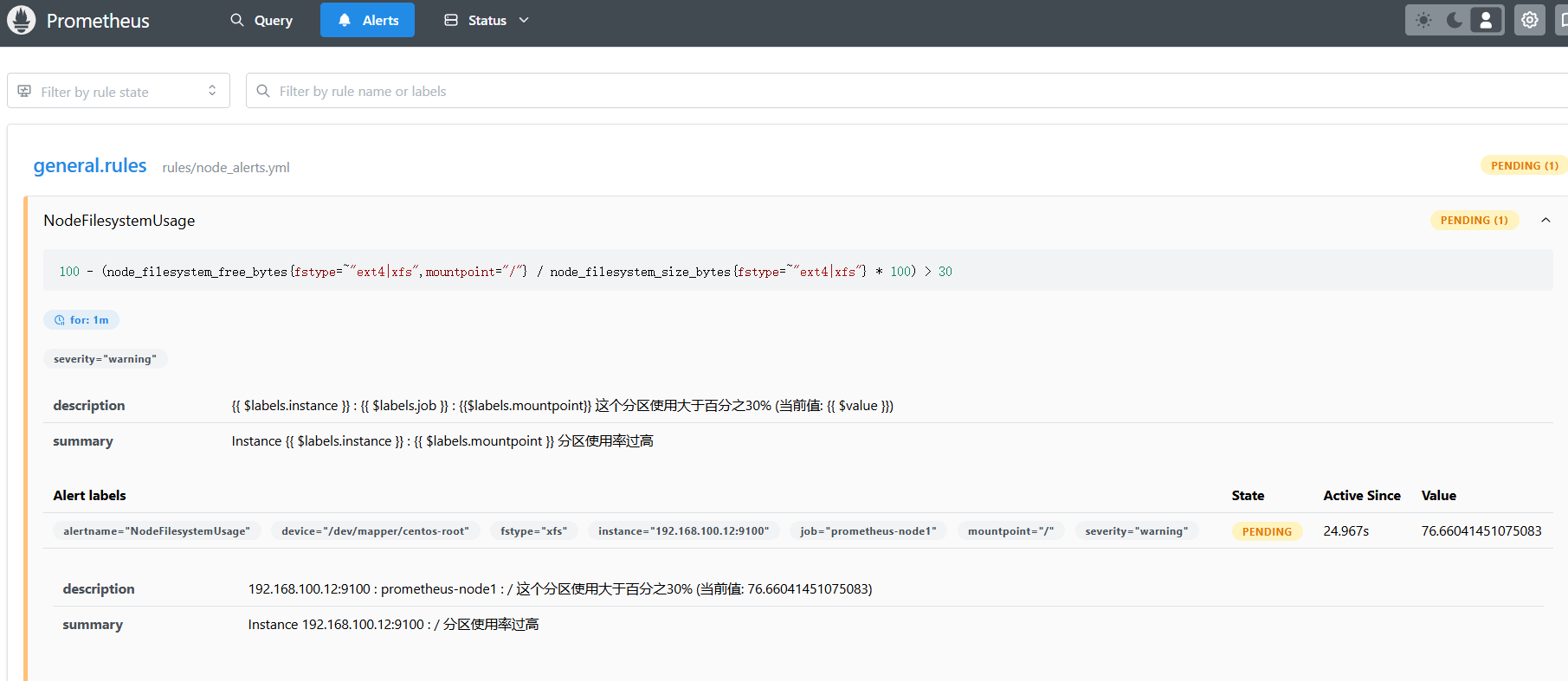
[root@localhost prometheus]# mkdir rulesvim rules/node_alerts.yml
groups:
- name: general.rules
rules:
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 30
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} : {{ $labels.mountpoint }} 分区使用率过高"
description: "{{ $labels.instance }} : {{ $labels.job }} : {{$labels.mountpoint}} 这个分区使用大于百分之30% (当前值: {{ $value }})"
重启prometheus
killall prometheus
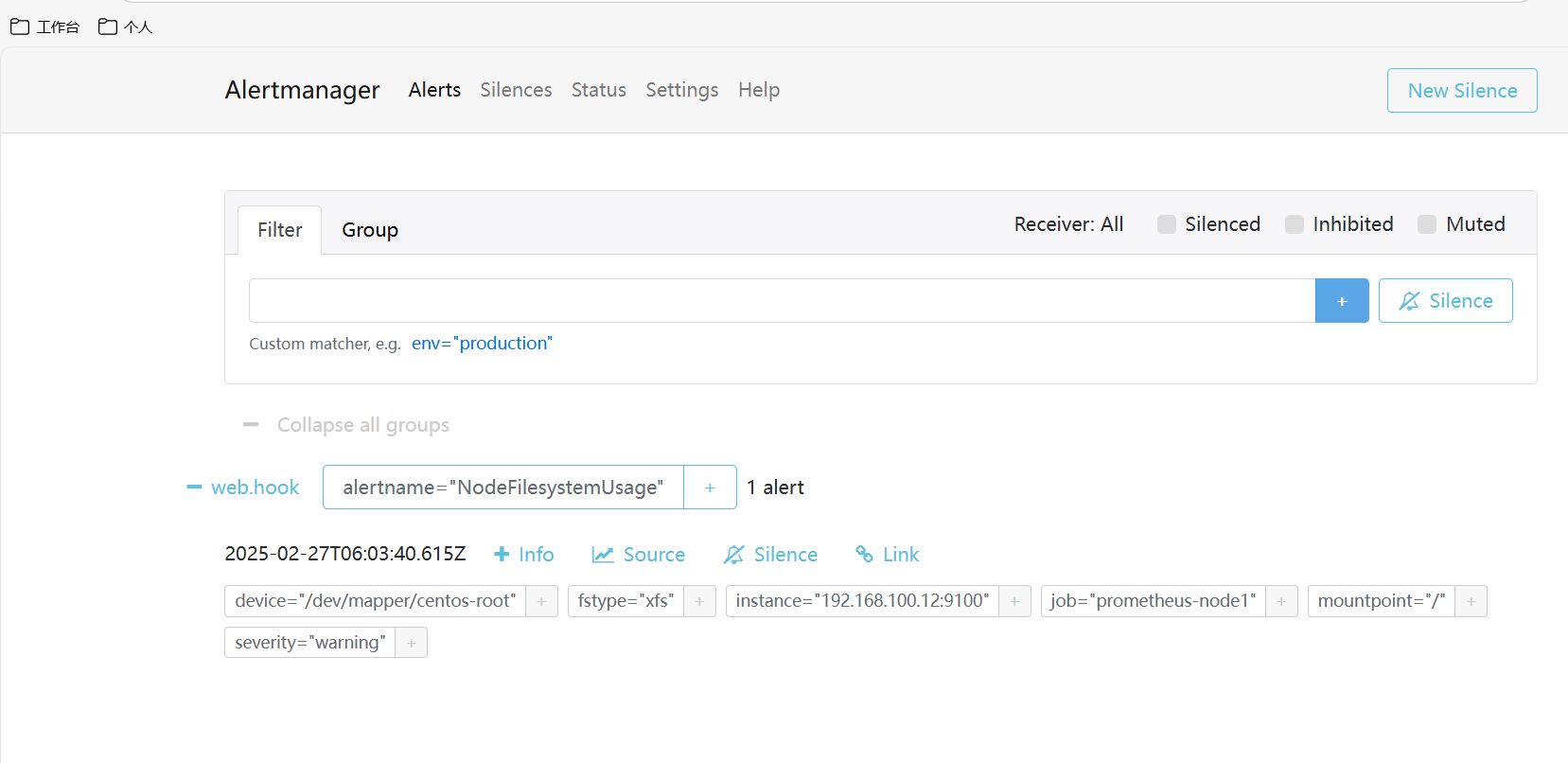
nohup ./prometheus --config.file=prometheus.yml &验证

七、export信息收集
到这里整个监控架构都搭建完成了,我们需要根据要求对特点资源进行监控,以及分类。(不包括k8s集群,集群由自动发现服务收集)
这里我没有环境仅对已知要求和临时搭建的环境做部署和测试
1、所有宿主服务器都安装ndoe_export监控主机状态 ( 第一章、2小结有教程)
get www.gmqgmq.cn/upload/node_exporter-1.8.2.linux-amd64.tar.gz
mkdir node-exporter
tar -zxvf node_exporter-1.8.2.linux-amd64.tar.gz -C node-exporter
#进入目录 启动服务
sudo nohup ./node_exporter &
#查看端口是否启用 有信息则正确
netstat -antp | grep 9100
#tcp6 0 0 :::9100 :::* LISTEN 6034/./node_exporte
#prometheus配置
- job_name: "prometheus-node1"
static_configs:
- targets: ["被监控端主机IP:端口"]2、针对Ai服务器 (所有的wget步骤都一样 下载解压 后面不在解释)
wget https://github.com/utkuozdemir/nvidia_gpu_exporter/releases/download/v1.2.0/nvidia_gpu_exporter_1.2.0_linux_x86_64.tar.gz
tar -zxvf nvidia_gpu_exporter_1.2.0_linux_x86_64.tar.gz -C nvidia-gpu
cd nvidia_gpu
sudo nohup ./nvidia_gpu_exporter &
- job_name: "deepseek-server-foun"
static_configs:
- targets: ["{agentIP:端口}"] #foun收集基础信息 这里就是node服务的IP:端口 3、监控mysql、mariadb
在数据库中创建一个仅用于监控的用户,并授予必要权限:
#下载插件
wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.17.2/mysqld_exporter-0.17.2.linux-arm64.tar.gz
tar -xzf mysqld_exporter-v0.17.2.linux-amd64.tar.gz
sudo mv mysqld_exporter-v0.17.2.linux-amd64/mysqld_exporter /usr/local/bin/
#创建 MySQL 监控用户
CREATE USER 'exporter'@'localhost' IDENTIFIED BY '密码'; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';
#配置并运行
echo "[client]
user=exporter
password=密码" > ~/.my.cnf
nohup ./mysqld_exporter --config.my-cnf=~/.my.cnf &
#prometheus配置
scrape_configs:
- job_name: 'mysql'
static_configs:
- targets: ['mysqlIP:9104']4、监控DM数据库(这有一些问题没解决该服务待二次验证)
wget https://www.gmqgmq.cn/upload/dmdb_exporter-0.1-alpha.tar.gz
# 进入dmdb_exporter目录
# 1. 设置环境变量,不同平台配置不同的参数即可 windows GOOS=windows GOARCH=amd64
$env:GOOS = "linux"
$env:GOARCH = "amd64"
# 2.查看环境变量
go env
# 3.执行打包
go build -o dmdb_exporter打包完成后,需要将目录下生成的二进制文件dmdb_exporter和default-metrics.toml都上传到服务器进行启动。注意需要给执行权限
chmod +x dmdb_exporter
export DATA_SOURCE_NAME=dm://SYSDBA:SYSDBA@localhost:5236?autoCommit=true
./dmdb_exporter --log.level=info --default.metrics=default-metrics.toml --web.listen-address=:91615、监控金仓
使用 postgres_exporter(适配金仓,因其基于 PostgreSQL)。
wget https://github.com/prometheus-community/postgres_exporter/releases/download/v0.17.0/postgres_exporter-0.17.0.linux-amd64.tar.gz
tar -xzf postgres_exporter-v0.17.0.linux-amd64.tar.gz
sudo mv postgres_exporter-v0.17.0.linux-amd64/postgres_exporter /usr/local/bin/
postgres_exporter --web.listen-address=:9187 --database-url="postgres://user:password@localhost:5432/dbname" &
scrape_configs:
- job_name: 'kingbase'
static_configs:
- targets: ['localhost:9187']6、Redis
wget https://github.com/oliver006/redis_exporter/releases/download/v1.67.0/redis_exporter-v1.67.0.linux-amd64.tar.gz
tar -xzf redis_exporter-v1.67.0.linux-amd64.tar.gz
sudo mv redis_exporter-v1.67.0.linux-amd64/redis_exporter /usr/local/bin/
redis_exporter --redis.addr=localhost:6379 &
scrape_configs:
- job_name: 'redis'
static_configs:
- targets: ['localhost:9121']7、监控 RabbitMQ
RabbitMQ 自带 Prometheus 插件,无需额外下载 Exporter,只需启用插件。
rabbitmq-plugins enable rabbitmq_prometheus
#Prometheus
scrape_configs:
- job_name: 'rabbitmq'
static_configs:
- targets: ['localhost:15692']8、监控API接口
Prometheus 要求应用程序以 /metrics 端点暴露指标,格式为 Prometheus 可解析的文本(如 key value 对)。根据您的应用程序语言,选择合适的实现方式
若无特殊要求和情况,公司原有API是有暴露端口的 直接将原API接口的配置信息 转移到新的prometheus配置文件中就可以,对项目进行分类 在Prometheus中使用tables针对不同项目接口进行划分
X、K8s子节点配置prometheus
在K8s中部署prometheus\RBAC
创建namespace:kubectl create namespace monitoring
apiVersion: v1
kind: "Service"
metadata:
name: prometheus
namespace: monitoring
labels:
name: prometheus
spec:
ports:
- name: prometheus
protocol: TCP
port: 9090
targetPort: 9090
nodePort: 30946
selector:
app: prometheus
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: prometheus
name: prometheus
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus
containers:
- name: prometheus
image: prom/prometheus:v2.3.0
env:
- name: ver
value: "15"
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--log.level=debug"
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: "/etc/prometheus"
name: prometheus-config
volumes:
- name: prometheus-config
configMap:
name: prometheus-configapiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
#node发现模式的授权资源,不然通过kubelet自带的发现模式不授权这个资源,会在prometheus爆出403错误
- nodes/metrics
- nodes/proxy
- services
- endpoints
- pods
- namespaces
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics","/api/*"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitoring配置prometheus_config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'cn-lcm-prod-kubernetes-kubelet'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
- job_name: 'cn-web-prod-kubernetes-cadvisor'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'cn-lcm-prod-kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'cn-lcm-prod-kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- target_label: __address__
replacement: kubernetes.default.svc:443
- job_name: 'cn-lcm-prod-kubernetes-services'
metrics_path: /probe
params:
module: [http_2xx]
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.monitoring.svc.cluster.local:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name
- job_name: 'cn-lcm-prod-kubernetes-ingresses'
metrics_path: /probe
params:
module: [http_2xx]
kubernetes_sd_configs:
- role: ingress
relabel_configs:
- source_labels: [__meta_kubernetes_ingress_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__meta_kubernetes_ingress_scheme,__address__,__meta_kubernetes_ingress_path]
regex: (.+);(.+);(.+)
replacement: ${1}://${2}${3}
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.monitoring.svc.cluster.local:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_ingress_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_ingress_name]
target_label: kubernetes_name
- job_name: 'cn-lcm-prod-kubernetes-service-endpoints'
scrape_interval: 10s
scrape_timeout: 10s
#这个job配置不太一样,采集时间是10秒,因为使用全局配置的15秒,会出现拉取数据闪断的情况,所以,这里单独配置成10秒
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_nameX、Prometheus自动发现(收集 k8s中得服务和组件数据)
如果被监控目标基于k8s,那么被监控目标将会非常多,而且目标对象更改频率也非常高,这就导致添加监控目标非常繁琐。引入服务发现机制就是为了实现自动将被监控目标添加到Prometheus里。在监控kubernetes的应用场景中,频繁更新的pod,svc,等等资源配置应该是最能体Prometheus监控目标自动发现服务的好处。下面我们使用consul的形式来实现自动发现
1、安装helm
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
# 删除原有仓库
helm repo remove bitnami
# 添加阿里云镜像的Bitnami仓库
helm repo add bitnami https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
# 更新仓库
helm repo update2、安装consul
在k8s中起一个consul服务
helm pull bitnami/consul
tar -zxvf consul-1.3.1.tgz
cd consul
helm install prometheus-consul .