常用中间件集群部署
redis—cluster集群部署
安装redis(多节点同步)
#拉取软件包 到服务器中
wget https://download.redis.io/releases/redis-6.2.1.tar.gz
#创建服务目录
mkdir /data/tysf-test/redis/
#解压到规划目录中
tar -zxvf redis-6.2.1.tar.gz -C /data/tysf-test/redis/
#进入解压目录进行编译
make && make install修改配置文件(三台redis端口不要冲突,将配置文件复制给另外几台,看你是6节点部署还是3节点一个道理)
port 16379 #端口16379
bind 本机ip #默认ip为172.20.0.2/3/4/5/6/7需要改为其他节点机器可访问的ip 否则创建集群时无法访问对应的端口,无法创建集群
daemonize yes #redis后台运行
pidfile /var/run/redis_16379.pid #pidfile #文件对应16379
cluster-enabled yes #开启集群 把注释#去掉
cluster-config-file nodes_7000.conf #集群的配置 配置文件首次启动自动生成
cluster-node-timeout 15000 #请求超时 默认15秒,可自行设置
appendonly yes #aof日志开启 有需要就开启,它会每次写操作都记录一条日志
masterauth '86a1b907d54bf7010394bf316e183e67'
requirepass '86a1b907d54bf7010394bf316e183e67' #设置密码启动redis
redis-server /usr/local/redis_cluster/redis.conf创建集群 说明:《0,1 这是对应你集群的模式是1主配一从还是都是主,根据实际情况来》
redis-cli --cluster create 172.17.9.48:16379 172.17.9.211:16380 172.17.9.91:16381 --cluster-replicas 《0,1》 -a "Rpb7H7wS076XPqBF"Kafka—Kraft模式 集群部署
前言:
kafka有两种模式 可以自己去了解一下这里就不多说了
集群规划:
一般模式下,元数据在 zookeeper 中,运行时动态选举 controller,由controller 进行 Kafka 集群管理。kraft 模式架构(实验性)下,不再依赖 zookeeper 集群,而是用三台 controller 节点代替 zookeeper,元数据保存在 controller 中,由 controller 直接进行 Kafka 集群管理。
好处有以下几个:
Kafka 不再依赖外部框架,而是能够独立运行
controller 管理集群时,不再需要从 zookeeper 中先读取数据,集群性能上升
由于不依赖 zookeeper,集群扩展时不再受到 zookeeper 读写能力限制
controller 不再动态选举,而是由配置文件规定。可以有针对性的加强controller 节点的配置,而不是像以前一样对随机 controller 节点的高负载束手无策。
下载二进制安装包:
https://kafka.apache.org/downloadscopy到三台节点上后解压:
mkdir /data/【项目名称-环境】/kafka
tar -zxvf /home/kafka_2.13-3.6.1.tgz -C /data/【项目名称-环境】/kafka调整配置文件:Kraft模式的配置文件在config目录的kraft子目录下
cd /data/【项目名称-环境】/kafka/kafka_2.13-3.6.1/config/kraft vi server.properties
server1.properties
# 节点类型,默认为混合节点
process.roles=broker,controller
# 节点id,为不小于1的整数
node.id=1
# 投票者列表:nodeId+地址端口
controller.quorum.voters=1@localhost:19093,2@localhost:19093,3@localhost:19093
# 内网地址
listeners=PLAINTEXT://:19092,CONTROLLER://:19093
inter.broker.listener.name=PLAINTEXT
# 外网地址
advertised.listeners=PLAINTEXT://localhost:19092
controller.listener.names=CONTROLLER
log.dirs=/tmp/kraft-combined-logs/log1server2.properties
# 节点类型,默认为混合节点
process.roles=broker,controller
# 节点id,为不小于1的整数
node.id=2
# 投票者列表:nodeId+地址端口
controller.quorum.voters=1@localhost:19093,2@localhost:19093,3@localhost:19093
# 内网地址
listeners=PLAINTEXT://:19092,CONTROLLER://:19093
inter.broker.listener.name=PLAINTEXT
# 外网地址
advertised.listeners=PLAINTEXT://localhost:19093
controller.listener.names=CONTROLLER
log.dirs=/tmp/kraft-combined-logs/log2server3.properties
# 节点类型,默认为混合节点
process.roles=broker,controller
# 节点id,为不小于1的整数
node.id=3
# 投票者列表:nodeId+地址端口
controller.quorum.voters=1@localhost:19093,2@localhost:19093,3@localhost:19093
# 内网地址
listeners=PLAINTEXT://:19092,CONTROLLER://:19093
inter.broker.listener.name=PLAINTEXT
# 外网地址
advertised.listeners=PLAINTEXT://localhost:19092
controller.listener.names=CONTROLLER
log.dirs=/tmp/kraft-combined-logs/log3生成集群ID并使用集群ID格式化数据目录
在KRaft模式下,一个集群需要设定一个id,我们可以使用自带的命令生成,先进入上述任意一台虚拟机并使用终端进入Kafka目录中,执行下列命令生成一个UUID:
bin/kafka-storage.sh random-uuid这里记录下这个ID以备用。kilMbKEoRUq3Ha6nruW6Aw
这个集群ID事实上是一个长度16位的字符串通过Base64编码后得来的,因此你也可以不使用上述命令,直接自定义一个16位长度的纯英文和数字组成的字符串,然后将这个字符串编码为Base64格式作为这个集群ID也可以。可以使用菜鸟工具中的在线Base64编码工具。
然后,分别执行下列命令,配置集群元数据:
./kafka-storage.sh format -t cKTMdVH_QZOJ_wEem1uz7w -c /data/tysf-test/Kafka/kafka_2.13-3.9.1/config/kraft/server.properties
./kafka-storage.sh format -t cKTMdVH_QZOJ_wEem1uz7w -c /data/tysf-test/Kafka/kafka_2.13-3.9.1/config/kraft/server.properties
./kafka-storage.sh format -t cKTMdVH_QZOJ_wEem1uz7w -c /data/tysf-test/Kafka/kafka_2.13-3.9.1/config/kraft/server.properties 启动Kafka集群:
./kafka-server-start.sh -daemon /data/tysf-test/Kafka/kafka_2.13-3.9.1/config/kraft/server.properties
./kafka-server-start.sh -daemon /data/tysf-test/Kafka/kafka_2.13-3.9.1/config/kraft/server.properties
./kafka-server-start.sh -daemon /data/tysf-test/Kafka/kafka_2.13-3.9.1/config/kraft/server.properties查看服务是否已经互相通讯
netstat -anutp 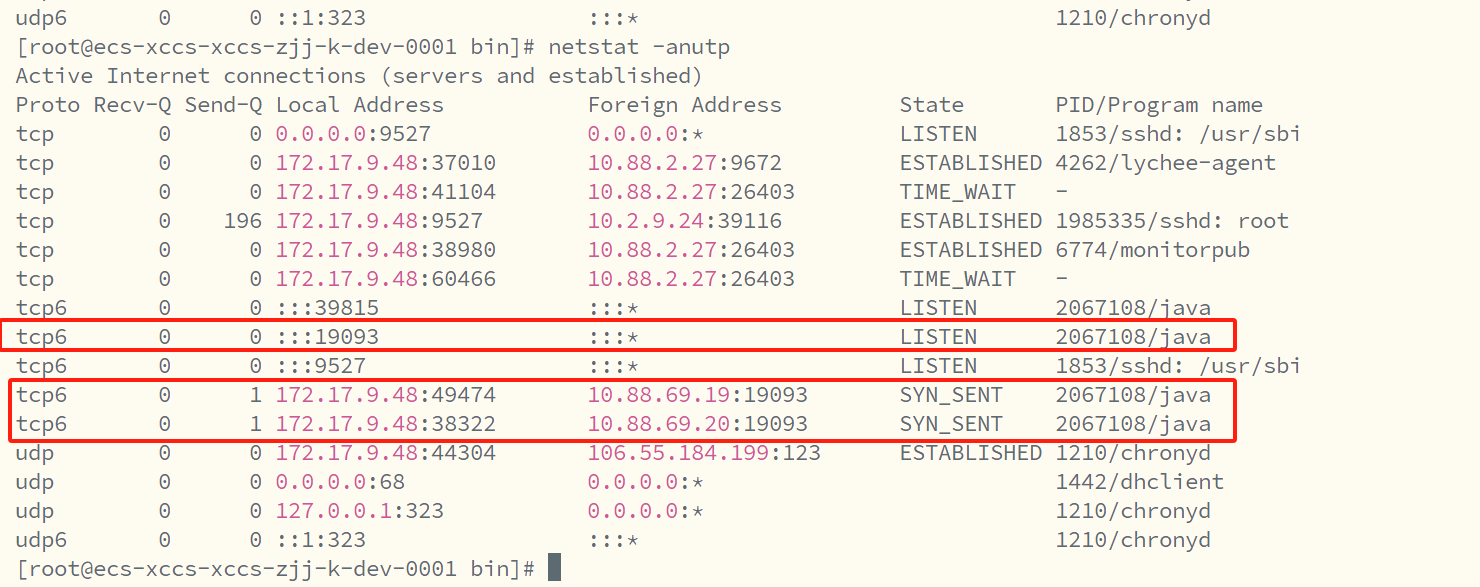
测试 在kafka1 上创建分区
./kafka-topics.sh --bootstrap-server "node1 IP":19092 -create --topic cluster-topic --partitions 3 --replication-factor 3在kafka2的端口(9094)查询该topic:
./kafka-topics.sh --bootstrap-server 172.17.9.211:19092 --describe --topic cluster-topic在kafka3的上删除该topic:
./kafka-topics.sh --bootstrap-server localhost:9096 --delete --topic cluster-topic Kafka模式 单节点部署
解压服务后编辑配置文件
mkdir /data/tysf-test/kafka/log
broker.id=0
listeners=PLAINTEXT://:9092
log.dirs=/tmp/kafka-logs
zookeeper.connect=localhost:2181Kafka 依赖于 ZooKeeper 来管理集群状态。首先启动 ZooKeeper:
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &启动kafka
nohup bin/kafka-server-start.sh config/server.properties &查看2181 与 9092端口
elasticsearch高可用集群部署(ELK日志分析)
ES角色说明:
主节点(Master Node)
活跃主节点(active master node):集群中只允许有一个活跃的主节点,负责轻量级集群范围的操作,例如创建或删除索引、跟踪集群成员以及决定分片的分配。拥有一个稳定的主节点对于集群健康很重要。(也就是如果你配置了多个主节点,实际活跃的主节点只有一个,其他为候选主节点)
数据节点(Data Node)
数据节点主要负责数据的存储和处理,包括数据的增删改查、搜索和聚合等操作。这些操作是I/O密集型、内存密集型和CPU密集型的,因此监控这些资源并在它们过载时添加更多数据节点非常重要。
协调节点(Coordinating Node)
协调节点主要负责协调客户端的请求,将接收到的请求分发给合适的节点,并把结果汇集到一起返回给客户端。每个节点都默认起到了协调节点的职责。(默认每个节点都是协调节点,故而不用特定当前节点为协调节点)
系统参数调整(所有系统都调整)
# 修改系统参数
cat >> /etc/security/limits.conf << 'EOF'
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
EOF
#用于限制一个进程可以拥有的最大内存映射区域数量。
echo "vm.max_map_count=655360" >> /etc/sysctl.conf
#让配置生效
sysctl -p解释:
oft nofile 65536:表示软性限制下,一个进程最多能打开的文件描述符(或句柄)数量为65536。软性限制是一个警告阈值,当达到或超过这个限制时,系统会给出警告,但进程仍然可以继续运行(取决于系统配置和策略)。
hard nofile 131072:表示硬性限制下,一个进程最多能打开的文件描述符数量为131072。硬性限制是一个严格的阈值,当达到或超过这个限制时,系统会拒绝进程打开更多的文件,并可能导致进程出错。
soft nproc 2048:表示软性限制下,一个用户最多能创建的进程数量为2048。同样,这是一个警告阈值。
hard nproc 4096:表示硬性限制下,一个用户最多能创建的进程数量为4096。这是一个严格的阈值,当达到或超过这个限制时,系统会拒绝用户创建更多的进程。
安装JDK:选择对应的版本安装 这里有所以跳过
三台节点互相配置hosts解析
下载需要的服务版本,上传到服务器
https://www.elastic.co/downloads/past-releases/tar -zxvf elasticsearch-7.17.13-linux-x86_64.tar.gz -C /data/tysf-test/elasticsearch/生成ES的证书(用于ES节点之间进行安全数据传输)
注:中一个ES节点执行,生成证书后拷贝到其他服务器的ES节点上
生成CA证书和节点证书
#生成CA根证书(注:执行命令后会提示你输入密码之类的,一直回车即可)
[root@es8-1 elasticsearch-8.15.0]# ./bin/elasticsearch-certutil ca
#生成节点证书并指定CA根证书(注:执行命令后会提示你输入密码之类的,一直回车即可)
[root@es8-1 elasticsearch-8.15.0]# ./bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12
将证书移动到ES的config目录或config子目录之下!!!(不然后续ES会启动报错)
[root@es8-1 elasticsearch-8.15.0]# mkdir /data/tysf-test/elasticsearch/elasticsearch-7.17.13/config/cert
[root@es8-1 elasticsearch-8.15.0]# mv *.p12 /data/tysf-test/elasticsearch/elasticsearch-7.17.13/config/cert
#传到另外两台服务器相同目录下注1:执行生成证书命令后会提示你输入密码之类的,一直回车即可
注2:生成证书后,看到当前目录下多了两个证书文件,elastic-stack-ca.p12(CA根证书)、elastic-certificates.p12(节点证书)
注3:在其中一个es节点中生成好证书后,将证书下载并上传到其他几台ES服务器上的es的配置目录下。
“注4”:一定要把生成的SSL证书放到ES的config目录之下,不然后续启动会报错!!
修改ES 相关配置文件
修改jvm.options文件
#编辑jvm文件,修改jvm的堆大小(根据实际情况来)
[root@es8-1 elasticsearch-8.15.0]# vim config/jvm.options
-Xms10g
-Xmx10g
#创建数据目录
mkdir -p /data/tysf-test/elasticsearch/{data,logs}修改elasticsearch.yml文件
[root@es8-1 elasticsearch-8.15.0]# vim config/elasticsearch.yml主要修改的参数如下:
#集群名称
cluster.name: es-cluster
#主机名(互相要配置hosts)
node.name: ecs-xccs-xccs-zjj-k-dev-0001.novalocal
#jie'd节点模式
node.roles: [master,data]
#数据目录目录以及日志目录
path.data: /data/tysf-test/elasticsearch/data
path.logs: /data/tysf-test/elasticsearch/logs
#搜索所有主机
network.host: 0.0.0.0
#外部访问端口
http.port: 9200
#集群内部访问的通讯duan端口
discovery.seed_hosts: ["172.17.9.48:9300","172.17.9.211:9300","172.17.9.91:9300"]
#注意这里找的主机是你hosts配置的集群节点,不配置找不到
cluster.initial_master_nodes: ["ecs-xccs-xccs-zjj-k-dev-0001.novalocal","ecs-xccs-xccs-zjj-k-dev-0002.novalocal","ecs-xccs-xccs-zjj-k-dev-0003.novalocal"]
action.destructive_requires_name: false
xpack.security.enabled: true
http.cors.enabled: true
http.cors.allow-origin: “*”
#上面配置的证书
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.client_authentication: required
xpack.security.transport.ssl.keystore.path: /data/tysf-test/elasticsearch/elasticsearch-7.17.13/config/cert/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /data/tysf-test/elasticsearch/elasticsearch-7.17.13/config/cert/elastic-certificates.p12创建es用户并启动
# 创建普通用户用于es
useradd -s /bin/bash elastic
#将es相关目录授权给es用户 1、数据目录 2、配置文件
chown -R elastic:elastic /data/tysf-test/elasticsearch
chown -R elastic:elastic /data/tysf-test/elasticsearch/elasticsearch-7.17.13自定义Systemctl来控制ES的启停:
cat > /etc/systemd/system/elasticsearch.service << 'EOF'
[Unit]
Description=Elastic Search
Documentation=https://www.elastic.co/docs
After=network.target
[Service]
Type=forking
#运行elasticsearch使用的用户
User=elastic
Group=elastic
ExecStart=/data/tysf-test/elasticsearch/elasticsearch-7.17.13/bin/elasticsearch -d
Restart=always
TimeoutStartSec=600s
RestartSec=650s
#设置进程的系统参数
LimitNOFILE=65536
LimitNPROC=4096
[Install]
WantedBy=multi-user.target
EOF
#让配置生效
systemctl daemon-reload启动ES
#启动es
systemctl start elasticsearch
#开机自启动
systemctl enable elasticsearch配置用户密码
/bin/elasticsearch-setup-passwords interactive
[root@ecs-xccs-xccs-zjj-k-dev-0001 elasticsearch-7.17.13]# ./bin/elasticsearch-setup-passwords interactive
Initiating the setup of passwords for reserved users elastic,apm_system,kibana,kibana_system,logstash_system,beats_system,remote_monitoring_user.You will be prompted to enter passwords as the process progresses.
Please confirm that you would like to continue [y/N]y
Enter password for [elastic]:
Reenter password for [elastic]:
Enter password for [apm_system]:
Reenter password for [apm_system]:
Enter password for [kibana_system]:
Reenter password for [kibana_system]:
Enter password for [logstash_system]:
Reenter password for [logstash_system]:
Enter password for [beats_system]:
Reenter password for [beats_system]:
Enter password for [remote_monitoring_user]:
Reenter password for [remote_monitoring_user]:
Changed password for user [apm_system]
Changed password for user [kibana_system]
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [beats_system]
Changed password for user [remote_monitoring_user]
Changed password for user [elastic]
[root@ecs-xccs-xccs-zjj-k-dev-0001 elasticsearch-7.17.13]# kibana安装与部署
选择ElasticSearch版本一致的Logstash版本
下载安装包:https://www.elastic.co/downloads/past-releases/kibana-7-17-13
解压到规划好的目录中
配置kibana
mkdir -p /data/xc-kibana/logs/kibana.log
vim data/xc-kibana-7.17.13-linux-x86_64/config/kibana.yml
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://172.17.9.48:9200","http://172.17.9.211:9200","http://172.17.9.91:9200"]
elasticsearch.username: "kibana_system"
elasticsearch.password: "iGj@lxxxxxxyX8uD"
i18n.locale: "zh-CN"
logging.appenders.default:
type: rolling-file
fileName: /data/xc-kibana/logs/kibana.log
policy:
type: size-limit
size: 256mb
strategy:
type: numeric
max: 2
layout:
type: pattern
pattern: "[%date][%level][%logger] %message"创建es用户并启动
# 创建普通用户用于es
useradd -s /bin/bash elastic
#将es相关目录授权给es用户 1、数据目录 2、配置文件
chown -R elastic:elastic /data/xc-kibana
chown -R elastic:elastic /data/xc-kibana/kibana-7.17.13-linux-x86_64自定义Systemctl来控制Kibana的启停
#自定义sytemctl来控制Kibana的启停
cat > /etc/systemd/system/kibana.service << 'EOF'
[Unit]
Description=Kibana
Documentation=https://www.elastic.co/docs
After=network.target
[Service]
#运行Kibana使用的用户
User=elastic
Group=elastic
ExecStart=/opt/software/kibana-8.15.0/bin/kibana
[Install]
WantedBy=multi-user.target
EOF
#让配置生效
systemctl daemon-reload启动
systemctl start kibana.service
systemctl enable kibana.service Logstash 安装与部署
选择ElasticSearch版本一致的Logstash版本
下载安装包
https://www.elastic.co/downloads/past-releases/logstash-7-17-13
解压到规划目录
编辑配置文件
PS:根据logstash-sample.conf模板规格来,想详细了解这一块的配置可以跳转:Logstash 安装与部署(无坑版)_logstash下载-CSDN博客
创建配置文件
vim /data/xc-logstash/logstash-7.17.13/config/llogstash-springboot.conf
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 5670
codec => json_lines
}
}
filter {
}
output {
elasticsearch {
hosts => ["http://172.17.9.48:9200","http://172.17.9.91:9200","http://172.17.9.211:9200"]
index => "log-goboy-dev-%{+yyyy.MM.dd}"
}
}指定配额
编辑config/pipelines.yml文件
pipeline.id指定该管道idpath.config指定ES和logstash连接的配置文件,就是上一步新建的conf文件的绝对路径
- pipeline.id: xc_log
path.config: "/data/xc-logstash/logstash-7.17.13/config/logstash-springboot.conf"Filebeat安装与部署
选择ElasticSearch版本一致的Logstash版本
下载安装包
https://www.elastic.co/downloads/past-releases/filebeat-7-17-13
解压到规划目录
进入filebeat-7.14.0-linux-x86_64文件夹,编辑filebeat.yml文件,这
# ------------------------------ Logstash inputs -------------------------------
#里只设置了输入格式为log的路径,同时把enable设置为true
filebeat.inputs:
- type: filestream
id: my-filestream-id
enabled: true
paths:
- /data/xc-filebeat/*.log
#这里的outputs设置,采用输出到logstash后再输入es的方式,因此将es output的配置注释,将logstash的配置打开并配置logstash的hosts
# ---------------------------- Elasticsearch Output ----------------------------
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "changeme"
# ------------------------------ Logstash Output -------------------------------
output.logstash:
# The Logstash hosts
hosts: ["172.17.9.156:5670"]检测配置文件
./filebeat test config
运行
nohup ./filebeat -e -c ./filebeat.yml &注意:
filebeat运行时要访问logstash,因此logstash要先于filebeat启动
RabbitMQ集群部署
RabbitMQ是一个开源的遵循AMQP协议实现的基于Erlang语言编写,支持多种客户端(语言),用于在分布式系统中存储消息,转发消息,具有高可用高可扩性,易用性等特征。
下载安装包: