Kafka—Kraft模式 集群安装与部署
前言:
kafka有两种模式 可以自己去了解一下这里就不多说了
集群规划:
一般模式下,元数据在 zookeeper 中,运行时动态选举 controller,由controller 进行 Kafka 集群管理。kraft 模式架构(实验性)下,不再依赖 zookeeper 集群,而是用三台 controller 节点代替 zookeeper,元数据保存在 controller 中,由 controller 直接进行 Kafka 集群管理。
好处有以下几个:
Kafka 不再依赖外部框架,而是能够独立运行
controller 管理集群时,不再需要从 zookeeper 中先读取数据,集群性能上升
由于不依赖 zookeeper,集群扩展时不再受到 zookeeper 读写能力限制
controller 不再动态选举,而是由配置文件规定。可以有针对性的加强controller 节点的配置,而不是像以前一样对随机 controller 节点的高负载束手无策。
下载二进制安装包:
copy到三台节点上后解压:
mkdir /data/【项目名称-环境】/kafka
tar -zxvf /home/kafka_2.13-3.6.1.tgz -C /data/【项目名称-环境】/kafka调整配置文件:Kraft模式的配置文件在config目录的kraft子目录下
cd /data/【项目名称-环境】/kafka/kafka_2.13-3.6.1/config/kraft vi server.properties
server1.properties
# 节点类型,默认为混合节点
process.roles=broker,controller
# 节点id,为不小于1的整数
node.id=1
# 投票者列表:nodeId+地址端口
controller.quorum.voters=1@localhost:19093,2@localhost:19093,3@localhost:19093
# 内网地址
listeners=PLAINTEXT://:19092,CONTROLLER://:19093
inter.broker.listener.name=PLAINTEXT
# 外网地址
advertised.listeners=PLAINTEXT://localhost:19092
controller.listener.names=CONTROLLER
log.dirs=/tmp/kraft-combined-logs/log1server2.properties
# 节点类型,默认为混合节点
process.roles=broker,controller
# 节点id,为不小于1的整数
node.id=2
# 投票者列表:nodeId+地址端口
controller.quorum.voters=1@localhost:19093,2@localhost:19093,3@localhost:19093
# 内网地址
listeners=PLAINTEXT://:19092,CONTROLLER://:19093
inter.broker.listener.name=PLAINTEXT
# 外网地址
advertised.listeners=PLAINTEXT://localhost:19093
controller.listener.names=CONTROLLER
log.dirs=/tmp/kraft-combined-logs/log2server3.properties
# 节点类型,默认为混合节点
process.roles=broker,controller
# 节点id,为不小于1的整数
node.id=3
# 投票者列表:nodeId+地址端口
controller.quorum.voters=1@localhost:19093,2@localhost:19093,3@localhost:19093
# 内网地址
listeners=PLAINTEXT://:19092,CONTROLLER://:19093
inter.broker.listener.name=PLAINTEXT
# 外网地址
advertised.listeners=PLAINTEXT://localhost:19092
controller.listener.names=CONTROLLER
log.dirs=/tmp/kraft-combined-logs/log3生成集群ID并使用集群ID格式化数据目录
在KRaft模式下,一个集群需要设定一个id,我们可以使用自带的命令生成,先进入上述任意一台虚拟机并使用终端进入Kafka目录中,执行下列命令生成一个UUID:
bin/kafka-storage.sh random-uuid这里记录下这个ID以备用。kilMbKEoRUq3Ha6nruW6Aw
这个集群ID事实上是一个长度16位的字符串通过Base64编码后得来的,因此你也可以不使用上述命令,直接自定义一个16位长度的纯英文和数字组成的字符串,然后将这个字符串编码为Base64格式作为这个集群ID也可以。可以使用菜鸟工具中的在线Base64编码工具。
然后,分别执行下列命令,配置集群元数据:
./kafka-storage.sh format -t cKTMdVH_QZOJ_wEem1uz7w -c /data/tysf-test/Kafka/kafka_2.13-3.9.1/config/kraft/server.properties
./kafka-storage.sh format -t cKTMdVH_QZOJ_wEem1uz7w -c /data/tysf-test/Kafka/kafka_2.13-3.9.1/config/kraft/server.properties
./kafka-storage.sh format -t cKTMdVH_QZOJ_wEem1uz7w -c /data/tysf-test/Kafka/kafka_2.13-3.9.1/config/kraft/server.properties 启动Kafka集群:
./kafka-server-start.sh -daemon /data/tysf-test/Kafka/kafka_2.13-3.9.1/config/kraft/server.properties
./kafka-server-start.sh -daemon /data/tysf-test/Kafka/kafka_2.13-3.9.1/config/kraft/server.properties
./kafka-server-start.sh -daemon /data/tysf-test/Kafka/kafka_2.13-3.9.1/config/kraft/server.properties查看服务是否已经互相通讯
netstat -anutp 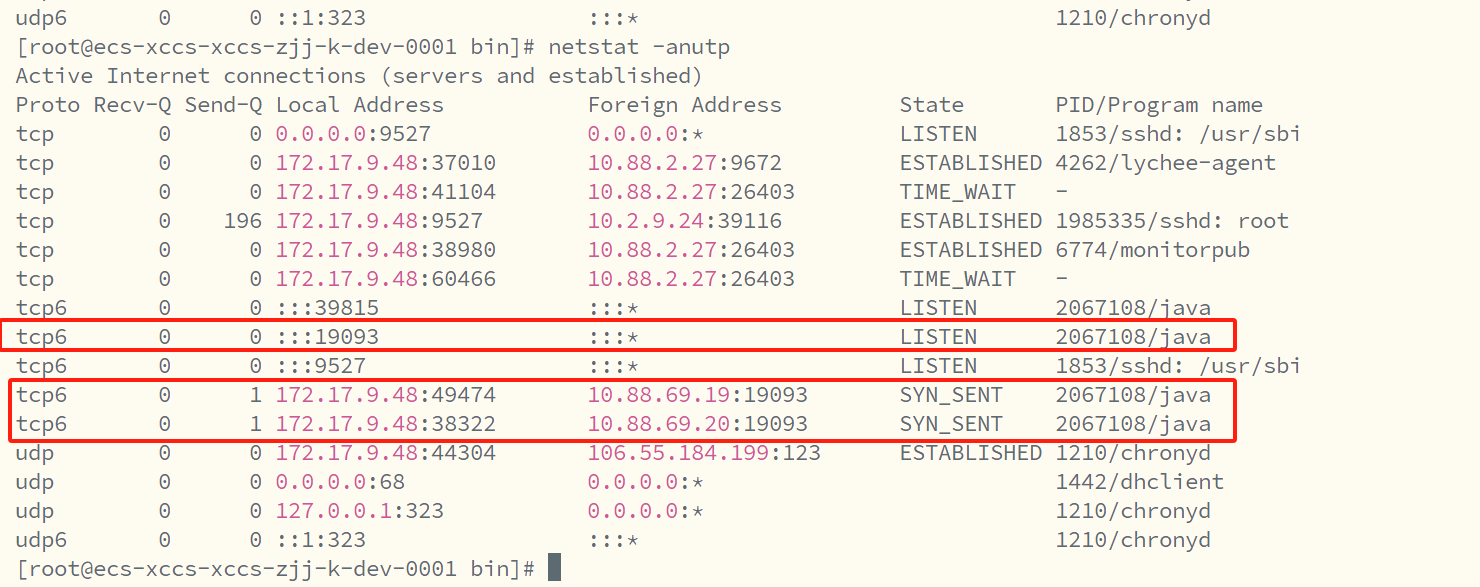
测试 在kafka1 上创建分区
./kafka-topics.sh --bootstrap-server "node1 IP":19092 -create --topic cluster-topic --partitions 3 --replication-factor 3在kafka2的端口(9094)查询该topic:
./kafka-topics.sh --bootstrap-server 172.17.9.211:19092 --describe --topic cluster-topic在kafka3的上删除该topic:
./kafka-topics.sh --bootstrap-server localhost:9096 --delete --topic cluster-topic