kubernetes+prometheus全套监控
部署目的:
再k8s集群外部有一个Grafana做汇总展示,prometheus部署到k8s环境监控集群,部署node_export监控集群主机的所有状态,部署kube-state-metrics监控组件和pod信息
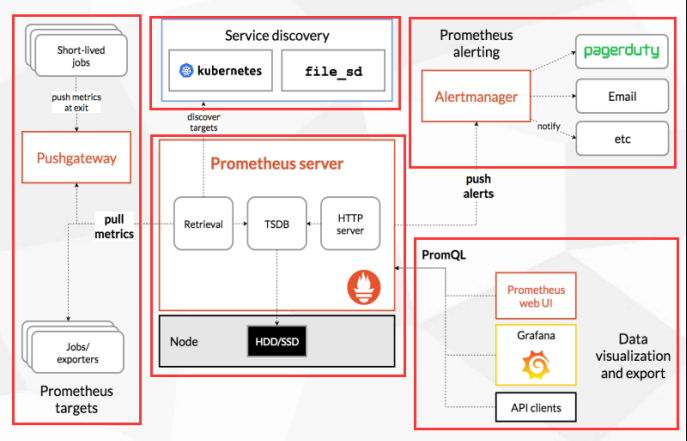
注意事项:集群的网络环境为内网环境 无法pull到公网的仓库镜像,所以这里只能手动拉取 让pod去找本地的镜像,所以下面配置中都是强制本地拉取的。
一、部署Prometheus
先来创建rbac,因为部署它的主服务主进程要引用这几个服务
因为prometheus来连接你的API,从API中获取很多的指标
并且设置了绑定集群角色的权限,只能查看,不能修改
1、创建rbac
prometheus-rbac.yaml
# ServiceAccount保持不变
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitoring
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
# 更新ClusterRole API版本并修正资源路径
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups: [""]
resources:
- nodes
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources:
- configmaps
verbs: ["get"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
# 更新ClusterRoleBinding API版本
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitoring2、创建报警规则&资源收集的configmap(建议手动部署yaml 格式会有问题)
prometheus-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitoring
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
data:
prometheus.yml: |
rule_files:
- /etc/config/rules/*.rules
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
- job_name: kubernetes-nodes
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- job_name: kubernetes-apiservers
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: keep
regex: default;kubernetes;https
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_service_name
- __meta_kubernetes_endpoint_port_name
- job_name: kubernetes-nodes-kubelet
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: kubernetes-nodes-cadvisor
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __metrics_path__
replacement: /metrics/cadvisor
- job_name: kubernetes-service-endpoints
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- job_name: kubernetes-services
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module: [http_2xx]
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_probe
- source_labels:
- __address__
target_label: __param_target
- replacement: blackbox
target_label: __address__
- source_labels:
- __param_target
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:80"]再配置这个角色,这个就是配置告警规则的,这里分为两块告警规则,一个是通用的告警规则,适用所有的实例,如果实例要是挂了,然后发送告警,实例我们被监控端的agent,还有一个node角色,这个监控每个node的CPU、内存、磁盘利用率,在prometheus写告警值是通过promQL去写的,来查询一个数据来比对,如果符合这个比对的表达式,就是为真的情况下,去触发当前这条告警,比如就是下面这条,然后会将这条告警推送给alertmanager,它来处理这个信息的告警。
3、配置角色
expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80
prometheus-rules.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-rules
namespace: monitoring
data:
general.rules: |
groups:
- name: general.rules
rules:
- alert: InstanceDown
expr: up{job="kubernetes-nodes"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} 停止工作"
description: "{{ $labels.instance }} job {{ $labels.job }} 已经停止5分钟以上."
node.rules: |
groups:
- name: node.rules
rules:
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} : {{ $labels.mountpoint }} 分区使用率过高"
description: "{{ $labels.instance }}: {{ $labels.mountpoint }} 分区使用大于80% (当前值: {{ $value }})"
- alert: NodeMemoryUsage
expr: 100 - ((node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100) > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} 内存使用率过高"
description: "{{ $labels.instance }} 内存使用大于80% (当前值: {{ $value }})"
- alert: NodeCPUUsage
expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 60
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} CPU使用率过高"
description: "{{ $labels.instance }} CPU使用大于60% (当前值: {{ $value }})"4、配置NFS
#检查服务器是否自带了nfs
rpm -qa nfs-utils rpcbind
#创建数据目录
mkdir -p /data/prometheus
#给予权限
chmod 755 /data/prometheus
#配置目录权限
#vim /etc/exports
/data/share *(rw,sync,insecure,no_subtree_check,no_root_squash)
#重启服务
systemctl restart nfs
systemctl restart nfs-utils5、部署pv持久
prometheus-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: prometheus-pv
namespace: monitoring
labels:
app: prometheus
spec:
storageClassName: managed-nfs-storage # 必须与StatefulSet中的storageClassName一致
capacity:
storage: 16Gi # 与StatefulSet请求的容量一致
accessModes:
- ReadWriteOnce # 必须与StatefulSet中定义的accessModes一致
persistentVolumeReclaimPolicy: Retain # 推荐设置为Retain(手动清理数据)
nfs: # 以NFS为例,可替换为其他存储类型(如hostPath、Ceph等)
path: /data/prometheus # NFS服务器上的实际路径
server: 10.88.68.134 # NFS服务器IP地址6、部署statefulset
prometheus-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: prometheus
namespace: monitoring
labels:
k8s-app: prometheus
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v2.2.1
spec:
serviceName: "prometheus"
replicas: 1
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels:
k8s-app: prometheus
template:
metadata:
labels:
k8s-app: prometheus
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
priorityClassName: system-cluster-critical
serviceAccountName: prometheus
initContainers:
- name: "init-chown-data"
image: "library/busybox:latest"
imagePullPolicy: "IfNotPresent"
command: ["chown", "-R", "65534:65534", "/data"]
volumeMounts:
- name: prometheus-data
mountPath: /data
subPath: ""
containers:
- name: prometheus-server-configmap-reload
image: "jimmidyson/configmap-reload:latest-arm64"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://localhost:9090/-/reload
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
resources:
limits:
cpu: 10m
memory: 10Mi
requests:
cpu: 10m
memory: 10Mi
- name: prometheus-server
image: "prom/prometheus:latest"
imagePullPolicy: "IfNotPresent"
args:
- --config.file=/etc/config/prometheus.yml
- --storage.tsdb.path=/data
- --web.console.libraries=/etc/prometheus/console_libraries
- --web.console.templates=/etc/prometheus/consoles
- --web.enable-lifecycle
ports:
- containerPort: 9090
readinessProbe:
httpGet:
path: /-/ready
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
livenessProbe:
httpGet:
path: /-/healthy
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
# based on 10 running nodes with 30 pods each
resources:
limits:
cpu: 200m
memory: 1000Mi
requests:
cpu: 200m
memory: 1000Mi
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: prometheus-data
mountPath: /data
subPath: ""
- name: prometheus-rules
mountPath: /etc/config/rules
terminationGracePeriodSeconds: 300
volumes:
- name: config-volume
configMap:
name: prometheus-config
- name: prometheus-rules
configMap:
name: prometheus-rules
volumeClaimTemplates:
- metadata:
name: prometheus-data
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "16Gi"7、创建service
prometheus-service.yaml
kind: Service
apiVersion: v1
metadata:
name: prometheus
namespace: monitoring
labels:
kubernetes.io/name: "Prometheus"
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
type: NodePort
ports:
- name: http
port: 9090
protocol: TCP
targetPort: 9090
selector:
k8s-app: prometheus访问暴露的端口就可以访问到了
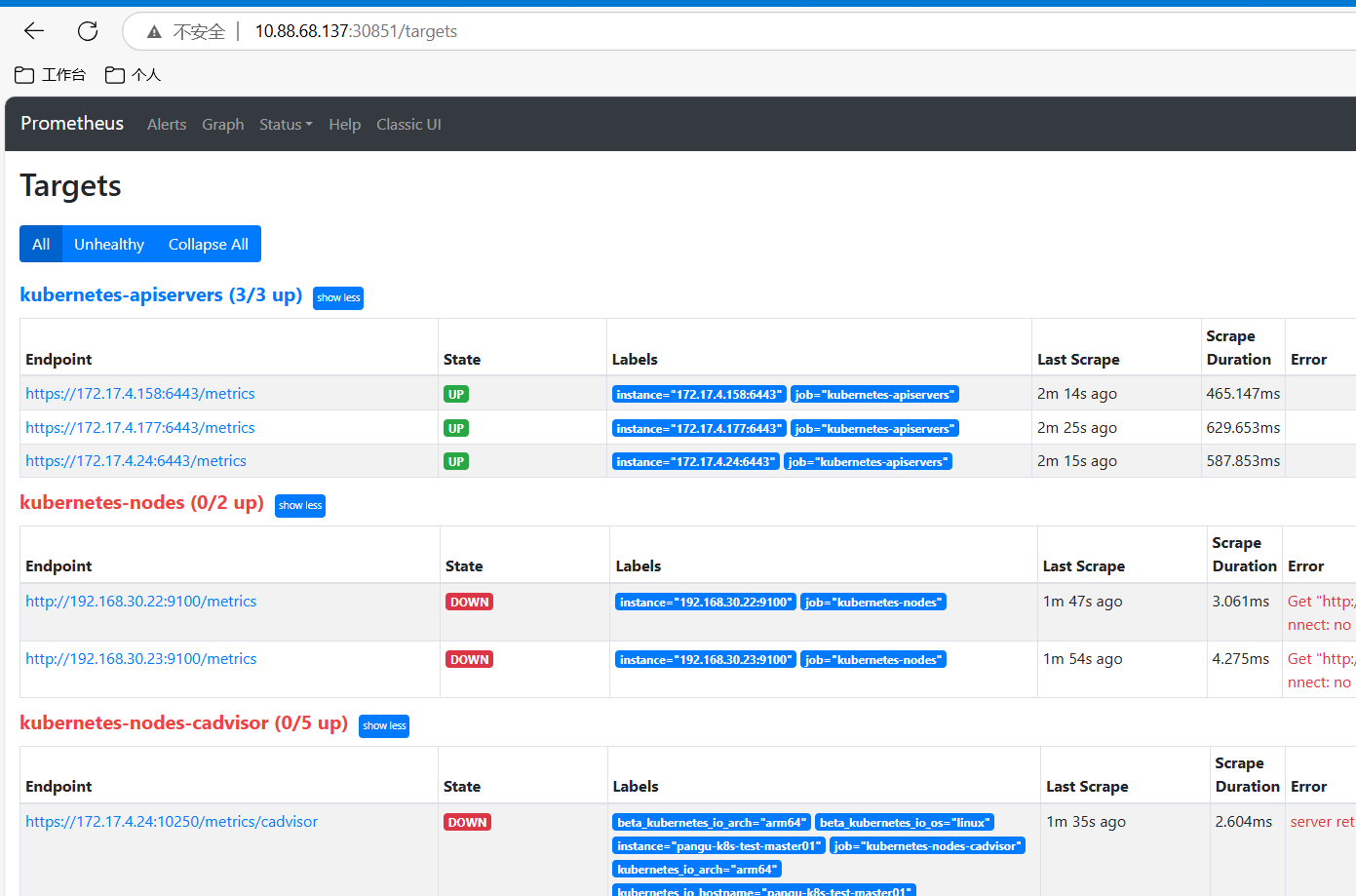
二、监控k8s的node
1、配置node_export的yaml文件
# prometheus-node-exporter.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitoring
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true #因为这里用的是hostNetwortk模式,所以后面就不需要创建svc了!
nodeSelector:
kubernetes.io/os: linux
containers:
- name: node-exporter
image: prom/node-exporter:v1.8.0
imagePullPolicy: "IfNotPresent"
args:
- --web.listen-address=$(HOSTIP):9100
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --path.rootfs=/host/root
- --no-collector.hwmon # 禁用不需要的一些采集器
- --no-collector.nfs
- --no-collector.nfsd
- --no-collector.nvme
- --no-collector.dmi
- --no-collector.arp
- --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/containerd/.+|/var/lib/docker/.+|var/lib/kubelet/pods/.+)($|/)
- --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$
ports:
- containerPort: 9100
env:
- name: HOSTIP
valueFrom:
fieldRef:
fieldPath: status.hostIP #Downward API
resources:
requests:
cpu: 150m
memory: 180Mi
limits:
cpu: 150m
memory: 180Mi
securityContext:
runAsNonRoot: true
runAsUser: 65534
volumeMounts:
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: root
mountPath: /host/root
mountPropagation: HostToContainer
readOnly: true
tolerations:
- operator: "Exists"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: root
hostPath:
path: /
因为上面configmap里定义了node的自动发现也就是下面的实例,所以我们可以直接访问prometheus看一下是否抓到了node
- job_name: kubernetes-nodes
kubernetes_sd_configs:
- role: node可以看到ndoe已经抓到了 但是报错 400Bad Request 这是因为他自动发现默认注册的端口为10250/metrics但我们配置的是9100

2、用 Prometheus 提供的 relabel_configs 中的 replace 能力
这里我们就需要使用到 Prometheus 提供的 relabel_configs 中的 replace 能力了,relabel 可以在 Prometheus 采集数据之前,通过 Target 实例的 Metadata 信息,动态重新写入 Label 的值。除此之外,我们还能根据 Target 实例的 Metadata 信息选择是否采集或者忽略该 Target 实例。比如我们这里就可以去匹配 address 这个 Label 标签,然后替换掉其中的端口,如果你不知道有哪些 Label 标签可以操作的话,可以在 Service Discovery 页面获取到相关的元标签,这些标签都是我们可以进行 Relabel 的标签
更改刚才的node自动发现
- job_name: kubernetes-nodes
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace三、监控k8s集群的资源
这个组件是官方开发的,通过API去获取k8s资源的状态,通过metrics来完成数据的采集。比如副本数是多少,当前是什么状态了,是获取这些的
1、创建rbac授权规则
#kube-state-metrics-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: monitoring
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups: [""]
resources:
- configmaps
- secrets
- nodes
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources:
- daemonsets
- deployments
- replicasets
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources:
- statefulsets
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources:
- cronjobs
- jobs
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources:
- horizontalpodautoscalers
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: kube-state-metrics-resizer
namespace: monitoring
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get"]
- apiGroups: ["extensions"]
resources:
- deployments
resourceNames: ["kube-state-metrics"]
verbs: ["get", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: kube-state-metrics
namespace: monitoring
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kube-state-metrics-resizer
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: monitoring2、创建deployment
#kube-state-metrics-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: monitoring
labels:
app: kube-state-metrics
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: bitnami/kube-state-metrics:latest
imagePullPolicy: "IfNotPresent"
ports:
- containerPort: 8080
name: http-metrics
resources:
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "200m"
memory: "256Mi"3、创建暴露的端口,这里使用的是service
#kube-state-metrics-service.yaml
apiVersion: v1
kind: Service
metadata:
name: kube-state-metrics
namespace: monitoring
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "kube-state-metrics"
annotations:
prometheus.io/scrape: 'true'
spec:
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
protocol: TCP
- name: telemetry
port: 8081
targetPort: telemetry
protocol: TCP
selector:
k8s-app: kube-state-metrics